Linux 内存管理
Memory 相关的术语说明
Main Memory- 也经常称为Physical Memory,计算机上的 Fast Data Storage Area。Virtual Memory- Main Memory 的一个抽象层,他几乎有无限大的空间,Virtual Memory 不是 Main MemoryResident Memory- 驻留(Reside)在 Main Memory 中的内存,相当于实际使用的物理内存(Main Memory/Physical Memory),如top命令中的RES、ps aux命令中的RSS就是指 Resident Memory.Anonymous Memory- 未关联文件系统位置和路径的内存,通常指 Process Address Space 中的程序运行过程中的数据(Working Data),通常被称为HeapAddress Space- 内存地址空间,内存地址相关的上下文(Context),包含程序(Processes)和内核(Kernel)使用的 Virtual Address SpaceSegment- 用于标识 Virtual Memory 中的有特殊作用的一个区域,如可执行程序(Executable)或可写(Writable)的 PageInstruction Text- CPU 指令(Instructions) 在内存中的引用地址,通常位于Segment中OOM- Out Of Memory,当内核检测到系统可用内存不足时采取的动作Page- OS 和 CPU 使用和分配内存的单位,早期大小一般为 4 或 8 Kbytes,现代化的 CPU 和 OS 通常支持 Multi Page SizesPage Fault- 通常在需要访问的内容不存在于 Virtual Memory 中时,系统产生一个中断,导致所需内容加载入内存Paging- 当内存中的内容不再使用或内存空间不足时进行的在内存和 Storage Devices 中的内容交换,主要是为了空出内存供需要内存的进程使用Swapping- Linux 中将不再使用或内存空间不足时,将部分内存中的内容 Paging 到 Swap DevicesSwap- Linux 中 Swapping 时,将内容转移到的目标,可能是 Storage Devices 上的一个区域,被称为 Physical Swap Device,或者是一个文件系统文件,称为 Swap File。
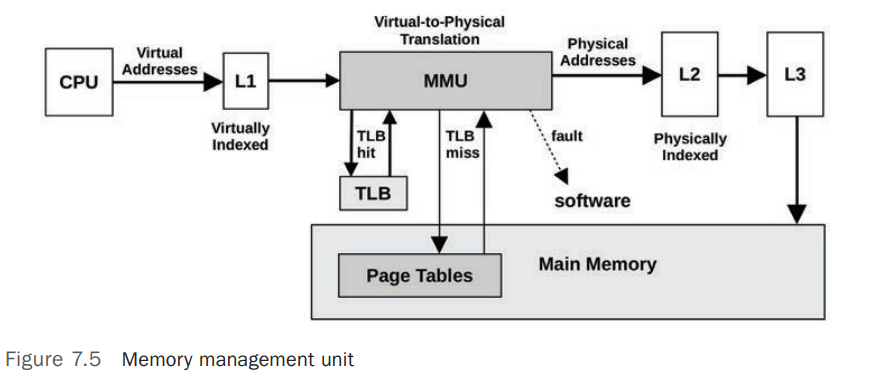
MMU
Memory Management Unit(MMU) 负责虚拟内存地址(Virtual Memory Address)到物理内存地址(Physical Memory Address)的转换
Freeing Memory
当系统上可用内存低或不足时,系统会采用一系列的手段释放内存。主要包括下图所示方式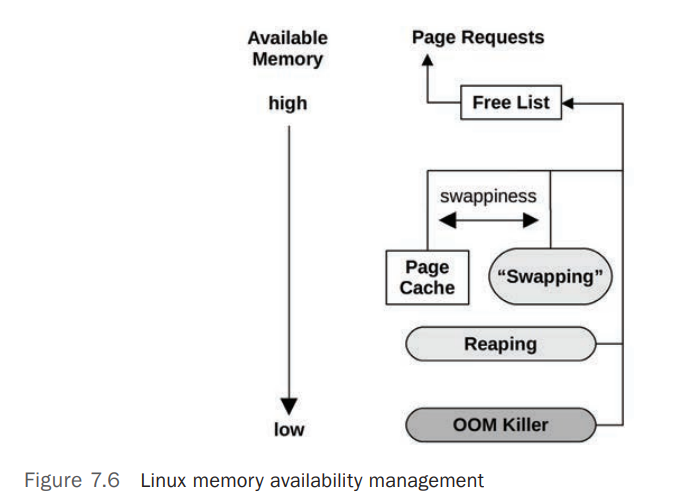
- Free List
不在使用中的 Pages 列表,也称为 Idle Memory,这部分内存可以被系统立即分配给需要的程序使用 - Page Cache
文件系统缓存(Filesystem Cache)。有个swappiness的参数可以配置系统是使用Page Cache还是Swapping来释放内存 - Swapping
通过内核进程kswapd实现 Paging Out 到 Swap Device 或者 File System-Based Swap File,这只有在系统上有 Swap 时才有用。 - Reaping
也被称为 Shrinking ,当系统可用内存小到一个临界值后,内核就会开始释放可以回收的内存 - OOM Killer
Out Of Memory Killer ,系统内存不足时,系统会使用 OOM Killer 机制来 kill 掉某个进程来释放内存。
在 Linux 中,当系统可用内存低于阈值(vm.min_free_kbytes)时,Page Out Daemon(kswapd) 会启动 Page Scanning ,
进程的内存分层结构
进程的内存结构一般被分成多个 segment,包括
Executable Text segment- 存放程序代码(the executable CPU Instructions), 只读Executable Data section- 存放程序初始化全局变量(global variables),通常 可读写 ,写权限用于程序运行期间更新变量值。Heap section- 程序运行过程中动态分配的内存,属于 Anonymous MemoryStack section- 调用程序功能时的临时数据存储,如函数参数、返回地址、本地变量等。
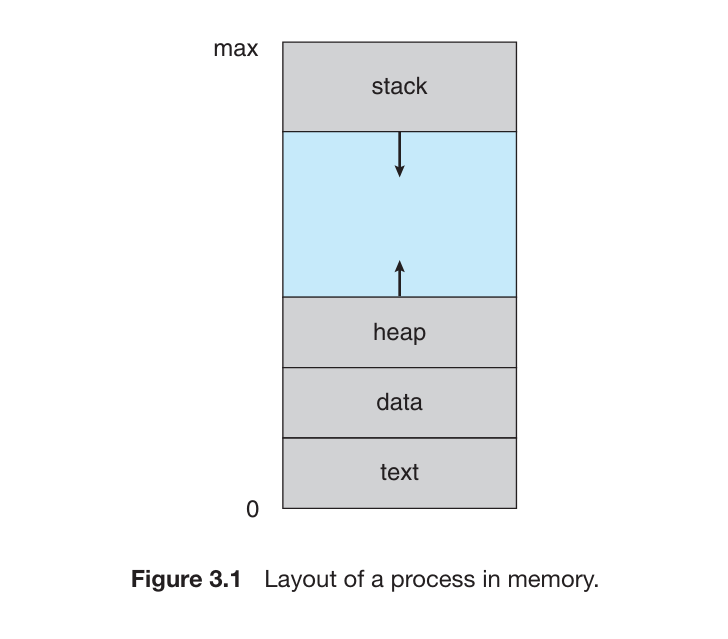
下图展示了 C 程序(Program)在内存中的分层结构(layout of a C program in memory)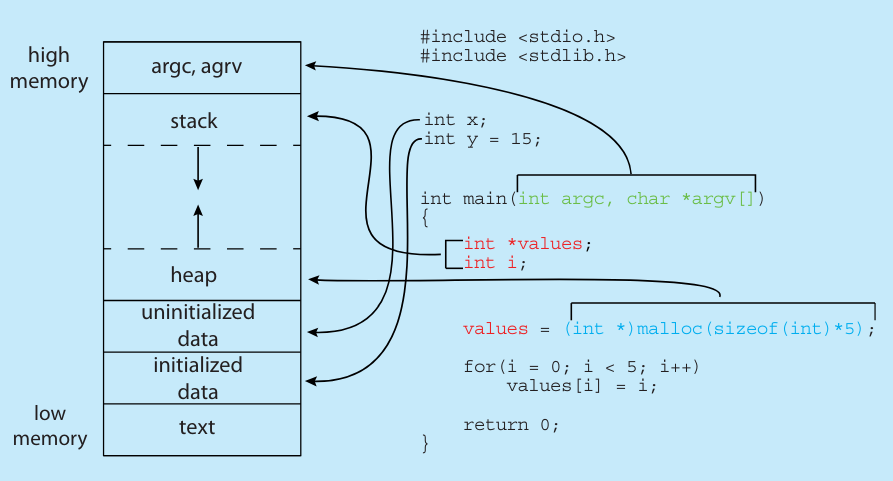
- 其中,
Data section被分成了 2 部分,包括(a) initialized data和(b) uninitialized data
使用 GNU 工具 size 可以检查 Projram 在磁盘上的 内存布局。这些值在程序编译时确定,并不会在程序运行时变化,因此它们是固定不变的。
size /usr/sbin/sshd |
输出信息中:
text: 代表Text section的大小data: 初始化数据段(initialized data)的大小,包含已初始化的全局和静态变量。bss: 未初始化数据段的大小,包含未初始化的全局和静态变量。dec: 上述所有部分的总大小,以十进制表示。hex: 上述所有部分的总大小,以十六进制表示。
OOM
OOM (Out-Of-memory) 是 Linux 内核机制(kernel reaper routine),用来确保系统始终有可用内存。当系统可用内存太低时,系统使用 OOM 机制 Kill 掉选中的进程以释放内存空间。Linux 中的每个进程有一个 OOM Score值,值越大,被 Kill 掉的可能性越大,OOM 值是根据所使用的内存占比计算而来,占用内存比例越高,OOM Score 越大。可以在 /proc/<PID>/oom_score 中看到 OOM Score 值
Slab
Linux 内核中的 slab 分配器(slab allocator) 是一种专门用于内核对象内存管理的内存分配机制。它最早由 Jeff Bonwick 在 SunOS 中引入,后来被移植到 Linux 内核中,用于高效地分配和回收小内核对象。
背景与动机
在内核中,许多数据结构(如
inode、dentry、task_struct、buffer_head等)通常较小且创建与销毁频繁。如果为每个对象单独申请一个完整的内存页(通常4KB),不仅浪费内存,还会增加内存分配与释放的开销。传统的分配器(如伙伴系统)虽然适合管理大块内存,但在处理大量小对象时容易导致内部碎片和效率低下。为了解决这一问题,内核引入了 slab 分配器,其目标是:- 高效重用 : 通过缓存已经分配好的内存块,避免重复初始化;
- 减少碎片 : 将内存按照对象大小进行预先划分,尽量减少内存浪费;
- 快速分配与释放 : 为频繁分配和释放的小对象提供更快的内存管理方案。
工作原理
slab Allocator 的基本思想是将内存分成一个个
slab(即内存块或缓存区),每个slab用来存储某一种类型的内核对象。其核心工作流程如下:预先分配
- 内核根据需要为某一类型的对象创建一个或多个
slab,每个slab包含多个固定大小的内存块。
对象缓存
- 当内核请求分配对象时,首先从相应类型的
slab缓存中查找空闲的内存块,如果有空闲块就直接返回并标记为使用中;如果没有,则从buddy分配器中申请新的内存页来创建新的slab。
对象释放
- 当对象不再使用时,不会立即释放回全局内存池,而是归还到
slab缓存中供以后重用。
回收和扩展
slab Allocator还会对slab的使用情况进行监控,若某个slab长时间没有被使用,可能会被回收;反之,若对象需求增加,则动态扩展slab缓存。
- 内核根据需要为某一类型的对象创建一个或多个
数据结构与实现
在 Linux 内核中,
slab Allocator(分配器)主要使用以下几个数据结构:slab cache(缓存)
每种需要频繁分配的对象都有一个对应的
slab cache(例如dentry_cache、inode_cache等)。该缓存记录了每个slab的信息,包括slab列表、空闲对象列表、对象大小等。slab(缓存块)
每个
slab是由一个或多个连续的内存页构成,内部划分为若干个相同大小的对象区域。每个slab维护一个链表,用于记录哪些对象是空闲的,哪些是正在使用的。对象(object)
每个对象就是一个固定大小的内存块,用于存储内核数据结构。对象的大小是固定的,由
slab cache在创建时确定。
常见的实现版本有 :
- SLAB : 早期的 slab 分配器实现;
- SLUB : 目前较常用的实现,代码更简单、调试更友好,并且对 NUMA 支持较好;
- SLOB : 专门针对内存资源较少的嵌入式系统设计,适用于内存较小的场景。
优势与不足
优势
- 效率高 :通过缓存机制避免了频繁的内存初始化和释放,提高了分配速度。
- 降低碎片化 :对象尺寸固定,内存分配更精细,减少了内部碎片问题。
- 重用性好 :内核对象一旦创建,可以在多个请求中反复使用,降低了整体内存开销。
- 实时性 :slab 分配器支持快速的对象分配和回收,满足内核对实时性的要求。
不足
- 内存占用问题 :为了保持一定的缓存,slab 分配器可能会预留一些未被使用的内存,导致一定的内存浪费,尤其在系统负载低时可能看起来 闲置 的内存较多。
- 复杂性 :对于内核开发者来说,slab 分配器的内部实现较为复杂,不同版本(SLAB、SLUB、SLOB)各有特点和调优方式。
系统管理员可以通过查看 /proc/slabinfo 和使用工具如 slabtop 来监控 Slab Allocator (分配器)的状态,观察哪些缓存占用内存较多,以便进行性能调优和内存泄漏检测。
slabtop -o |
Memory Paging
查看内存分页大小
getconf PAGESIZE |
清除系统内存中的分页缓存
如果系统内存不足或者定位内存相关问题,需要清空内存中的分页缓存(Memory Page Cache,将当前没有使用的所有内存分页要么写回到磁盘,要么丢弃),可以使用以下方法
echo 3 > /proc/sys/vm/drop_caches
内存状态监测工具
NUMA 架构及其性能统计数据
NUMA(Non-Uniform Memory Access) 架构是有多个处理器插槽(Multiple Processor Sockets)的系统常用 CPU Memory 架构。 NUMA 概念说明
使用 lscpu 命令可以查看系统上的 NUMA 信息,示例如下:
lscpu |
根据如上输出,可以得到以下 CPU 和 内存以及 NUMA 相关信息:
Socket(s): 2: 系统上存在 2 个物理处理器(2 个插槽中)Core(s) per socket: 14: 每个物理处理器有 14 个核心(Core)Thread(s) per core: 每个 Core 上有 2 个物理线程(即 2 个 CPU)。CPU(s): 56: 根据以上的信息,系统上总的 CPU 个数为 2(Sockets) * 14(Cores) * 2(Threads) = 56 CPUsOn-line CPU(s) list: 0-55: 所有 CPUs 都可正常工作(On-line),CPU 编号为 0-55NUMA node(s): 2: 这 56 个 CPU 被划分为 2 个 NUMA 节点(Node),分别为NUMA node0和NUMA node1NUMA node0 CPU(s):NUMA node0包含了编号为0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46,48,50,52,54的 CPUNUMA node1 CPU(s):NUMA node1包含了编号为1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43,45,47,49,51,53,55的 CPU
numastat
numastat 命令提供了 NUMA 相关的统计数据。numastat 在 numactl 包中,可能需要安装。通过 numastat 数据,可以有效定位 NUMA 相关的性能瓶颈并进行优化。
numastat |
以上示例显示系统上存在 2 个 NUMA Node,分别为 node0 和 node1,其他参数说明如下:
numa_hit: 该值表示处理器访问本地 NUMA 节点内存的次数。例如,node0的值为6095298439,意味着node0处理器访问其本地内存的次数为6095298439次。numa_miss: 该值表示处理器访问远程 NUMA 节点内存的次数,即访问不属于当前节点的内存。例如,node0的值为549449041,意味着node0处理器访问node1的内存的次数为549449041次。numa_foreign: 该值表示远程内存的访问次数,numa_foreign等同于numa_miss,只是它特别指向其他 NUMA 节点访问本节点的次数。interleave_hit: 该值表示跨节点间交替分配的内存访问命中的次数。在一些内存配置中,内存被分配为交替访问模式。例如,node0的值为34449,意味着有34449次跨节点交替分配的内存访问命中。local_node: 该值表示从当前节点访问本地节点内存的次数。例如,node0的值为6095331131,意味着node0节点访问了本地节点的内存6095331131次。other_node: 该值表示从当前节点访问其他节点的内存的次数。例如,node0的值为549416349,意味着node0节点访问了其他节点(node1)的内存549416349次。
如果要管理和分配 NUMA Node 内存和 CPU 分配,可以使用 Linux 内核提供的 NUMA 管理工具 numactrl
查看每个 NUMA Node 的内存使用详细情况
free -h |
以上输出中,相关字段说明如下:
Active: 活跃的内存页,即最近使用过的页,分为Active(anon)(匿名页)和Active(file)(文件页)。Inactive: 非活跃的内存页,可能被交换或回收,分为Inactive(anon)(匿名页)和Inactive(file)(文件页)。Anonymous Pages: 匿名页,通常是分配给进程的堆或栈,即程序运行过程中产生的数据File Pages: 文件缓存页,通常用于文件缓存Dirty: 脏页,尚未写入磁盘的页。文件在内存中已经更改,但是还未刷新写入磁盘Writeback: 正在写回磁盘的页。Mapped: 被映射到进程地址空间的内存页。AnonPages: 匿名页的总量。包括Active(anon)和Inactive(anon)Shmem: 使用共享内存的页。KernelStack: 分配给内核栈的内存。
根据以上输出信息可知,目前系统可用内存还有 8.2G,已使用 85G,根据 numastat -m 输出的信息,可以看到更为详细的内存使用情况:
- Node 0 的可用内存较多(
5300.99 MB),而 Node 1 几乎没有可用内存(52.67 MB)。 - Node 1 的
Active和AnonPages比 Node 0 高,可能表示有大量的进程绑定在 Node 1。 - 匿名页(
AnonPages)占据了绝大部分内存(总计83540.68 MB),表明进程分配的堆和栈内存较多。 - 文件页(
FilePages)总计只有555.29 MB,说明系统的 I/O 缓存使用较少,可能 I/O 压力较低。
根据以上分析,可以大致通过以下思路优化内存使用:
- Node 1 的内存使用接近极限(
MemFree仅52.67 MB)。如果可能,重新分配负载,平衡 NUMA 节点的内存压力。 - 如果内存分配倾斜严重,可以调整进程绑定策略(如使用
numactl或调整应用程序配置)。 - 匿名内存占用过高,可能需要分析应用程序的内存使用情况,优化分配或减少内存泄漏。
- 如果适用,可以启用大页(HugePages),减少页表开销。
查看指定进程在 NUMA Node 上的内存统计数据 ,可以看到进程在各个 NUMA Nodes 上使用的内存,进程可以使用 PID 或者进程名指定,具体规则请查看 man numastat
numastat -p nginx |
pmap
pmap 命令会显示进程的 Memory Mappings(内存地址映射),包括 内存地址 、 大小 、 权限 、 Mapped Objects(映射的对象) 。详细说明请参考 man pmap
pmap 19112 |
使用 -x, --extended 选项显示扩展信息,主要是显示更为详细的 Virtual Memory 和 RSS 信息
pmap -x 19112 |
使用 -X 或者 -XX 选项显示更详细的扩展信息
pmap -X 19112 |
使用 -p, --show-path 选项显示更详细的引用路径信息
pmap -x -p 19112 |
Memory Paging 性能数据监控
sar 命令的 -B Paging statistics 选项提供了内存 Paging 相关的统计数据。 sar -B 命令及输出字段解释
vmstat
vmstat 是一个系统全局性(System Wide)工具,主要用来监测 Virtual 和 Physical Memory 的统计数据
PSI
PSI(Pressure Stall Information) 是 Linux 4.20 引进的一个新特性,用于提供有关 CPU、内存和 IO 子系统的资源压力信息。PSI 帮助管理员和开发者理解系统的资源瓶颈,优化性能和可靠性。
cat /proc/pressure/memory |
在以上的 PSI 统计数据中,可以看出 Memory 压力在持续增加,10s 的平均延迟(2.84)比 300s 的平均延迟(0.32)大了很多。 这个延迟表述的是进程因为内存原因暂停等待的时间占比
内存压力测试工具
memtester
使用 docker 运行工具
$ docker run --rm -it dockerpinata/memtester:1 memtester |
stress 工具
stress 是一个用于模拟系统负载的工具,可以使用它来创建临时的内存负载。通过模拟负载,系统将使用更多的内存。
yum install -y stress |
使用以下命令可以创建一个临时的内存负载
stress --vm 1 --vm-bytes <MEMORY_SIZE> |
dd
dd 命令可以用于创建大文件并占用磁盘空间,从而间接提升系统的内存使用率。您可以使用以下命令创建一个指定大小的临时文件
dd if=/dev/zero of=tempfile bs=1M count=<MEMORY_SIZE> |
tmpfs
Linux 中 tmpfs 是一种基于内存的临时文件系统,它将内存作为存储介质,可以在需要快速读写文件的场景下使用。
注意事项:
tmpfs是基于内存的临时文件系统,因此上面的数据在系统重启后将丢失- 当
tmpfs文件系统使用的内存达到上限值,写入操作会失败,因此需要确保分配给tmpfs文件系统使用的内存适合需求 - 要确保系统有足够的可用内存来支持挂载
tmpfs文件系统。
tmpfs 使用步骤
- 创建一个目录作为文件系统挂载点
mkdir /mnt/ramdisk/
- 使用
mount命令以tmpfs的类型挂载文件系统这将在mount -t tmpfs -o size=1G tmpfs /mnt/ramdisk/
/mnt/ramdisk目录下挂载一个 1GB 大小的tmpfs文件系统。根据需要调整size参数的值。之后便可以像操作其他文件系统一样在/mnt/ramdisk目录下读写文件。任何写入该目录的数据都将存储在内存中。
参考链接|Bibliography
Systems Performance: Enterprise and the Cloud v2
脚注
- 1.Systems Performance: Enterprise and the Cloud v2 #7.1 Terminology ↩