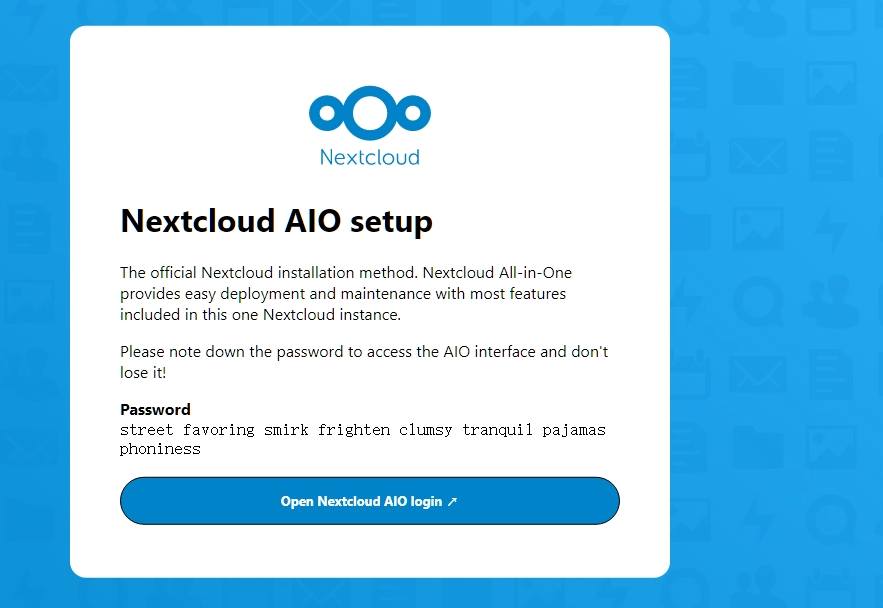
# curl localhost:8888/status
{"hostName":"testhost","moduleVersion":"v0.2.2","nginxVersion":"1.24.0","loadMsec":1713418497362,"nowMsec":1713418504352,"connections":{"active":7,"reading":0,"writing":1,"waiting":6,"accepted":7,"handled":7,"requests":14},"sharedZones":{"name":"ngx_http_vhost_traffic_status","maxSize":1048575,"usedSize":10587,"usedNode":3},"serverZones":{"api.testdomain.com":{"requestCounter":12,"inBytes":9330,"outBytes":6249,"responses":{"1xx":0,"2xx":12,"3xx":0,"4xx":0,"5xx":0,"miss":0,"bypass":0,"expired":0,"stale":0,"updating":0,"revalidated":0,"hit":0,"scarce":0},"requestMsecCounter":11,"requestMsec":0,"requestMsecs":{"times":[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1713418503612,1713418503612,1713418503612,1713418503612,1713418503612,1713418503962,1713418503965,1713418503965,1713418503966,1713418503966,1713418504330,1713418504331],"msecs":[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,3,1,3,3,0,0]},"requestBuckets":{"msecs":[],"counters":[]},"overCounts":{"maxIntegerSize":18446744073709551615,"requestCounter":0,"inBytes":0,"outBytes":0,"1xx":0,"2xx":0,"3xx":0,"4xx":0,"5xx":0,"miss":0,"bypass":0,"expired":0,"stale":0,"updating":0,"revalidated":0,"hit":0,"scarce":0,"requestMsecCounter":0}},"src.testdomain.ph":{"requestCounter":1,"inBytes":393,"outBytes":309,"responses":{"1xx":0,"2xx":0,"3xx":1,"4xx":0,"5xx":0,"miss":0,"bypass":0,"expired":0,"stale":0,"updating":0,"revalidated":0,"hit":0,"scarce":0},"requestMsecCounter":0,"requestMsec":0,"requestMsecs":{"times":[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1713418500180],"msecs":[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]},"requestBuckets":{"msecs":[],"counters":[]},"overCounts":{"maxIntegerSize":18446744073709551615,"requestCounter":0,"inBytes":0,"outBytes":0,"1xx":0,"2xx":0,"3xx":0,"4xx":0,"5xx":0,"miss":0,"bypass":0,"expired":0,"stale":0,"updating":0,"revalidated":0,"hit":0,"scarce":0,"requestMsecCounter":0}},"*":{"requestCounter":13,"inBytes":9723,"outBytes":6558,"responses":{"1xx":0,"2xx":12,"3xx":1,"4xx":0,"5xx":0,"miss":0,"bypass":0,"expired":0,"stale":0,"updating":0,"revalidated":0,"hit":0,"scarce":0},"requestMsecCounter":11,"requestMsec":0,"requestMsecs":{"times":[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1713418500180,1713418503612,1713418503612,1713418503612,1713418503612,1713418503612,1713418503962,1713418503965,1713418503965,1713418503966,1713418503966,1713418504330,1713418504331],"msecs":[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,3,1,3,3,0,0]},"requestBuckets":{"msecs":[],"counters":[]},"overCounts":{"maxIntegerSize":18446744073709551615,"requestCounter":0,"inBytes":0,"outBytes":0,"1xx":0,"2xx":0,"3xx":0,"4xx":0,"5xx":0,"miss":0,"bypass":0,"expired":0,"stale":0,"updating":0,"revalidated":0,"hit":0,"scarce":0,"requestMsecCounter":0}}},"upstreamZones":{"::nogroups":[{"server":"127.0.0.1:12000","requestCounter":5,"inBytes":4154,"outBytes":3351,"responses":{"1xx":0,"2xx":5,"3xx":0,"4xx":0,"5xx":0},"requestMsecCounter":11,"requestMsec":2,"requestMsecs":{"times":[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1713418503962,1713418503965,1713418503965,1713418503966,1713418503966],"msecs":[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,3,1,3,3]},"requestBuckets":{"msecs":[],"counters":[]},"responseMsecCounter":11,"responseMsec":2,"responseMsecs":{"times":[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1713418503962,1713418503965,1713418503965,1713418503966,1713418503966],"msecs":[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,3,1,3,3]},"responseBuckets":{"msecs":[],"counters":[]},"weight":0,"maxFails":0,"failTimeout":0,"backup":false,"down":false,"overCounts":{"maxIntegerSize":18446744073709551615,"requestCounter":0,"inBytes":0,"outBytes":0,"1xx":0,"2xx":0,"3xx":0,"4xx":0,"5xx":0,"requestMsecCounter":0,"responseMsecCounter":0}}]}}
|