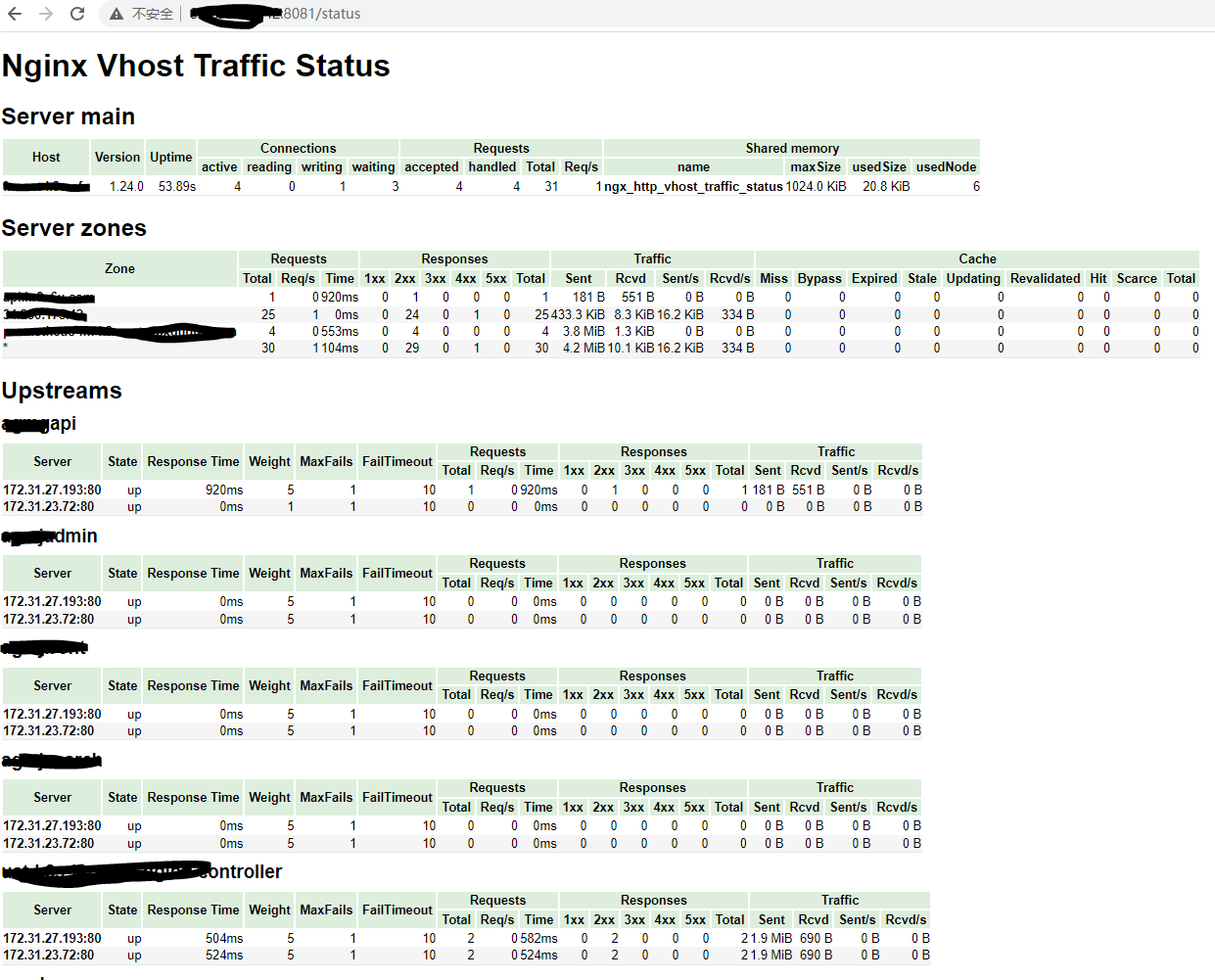
环境信息
- Kubernetes 1.24
- Vault 1.14.0
Vault 简介
Vault 架构及基础概念
Vault 的架构图如下 [1]
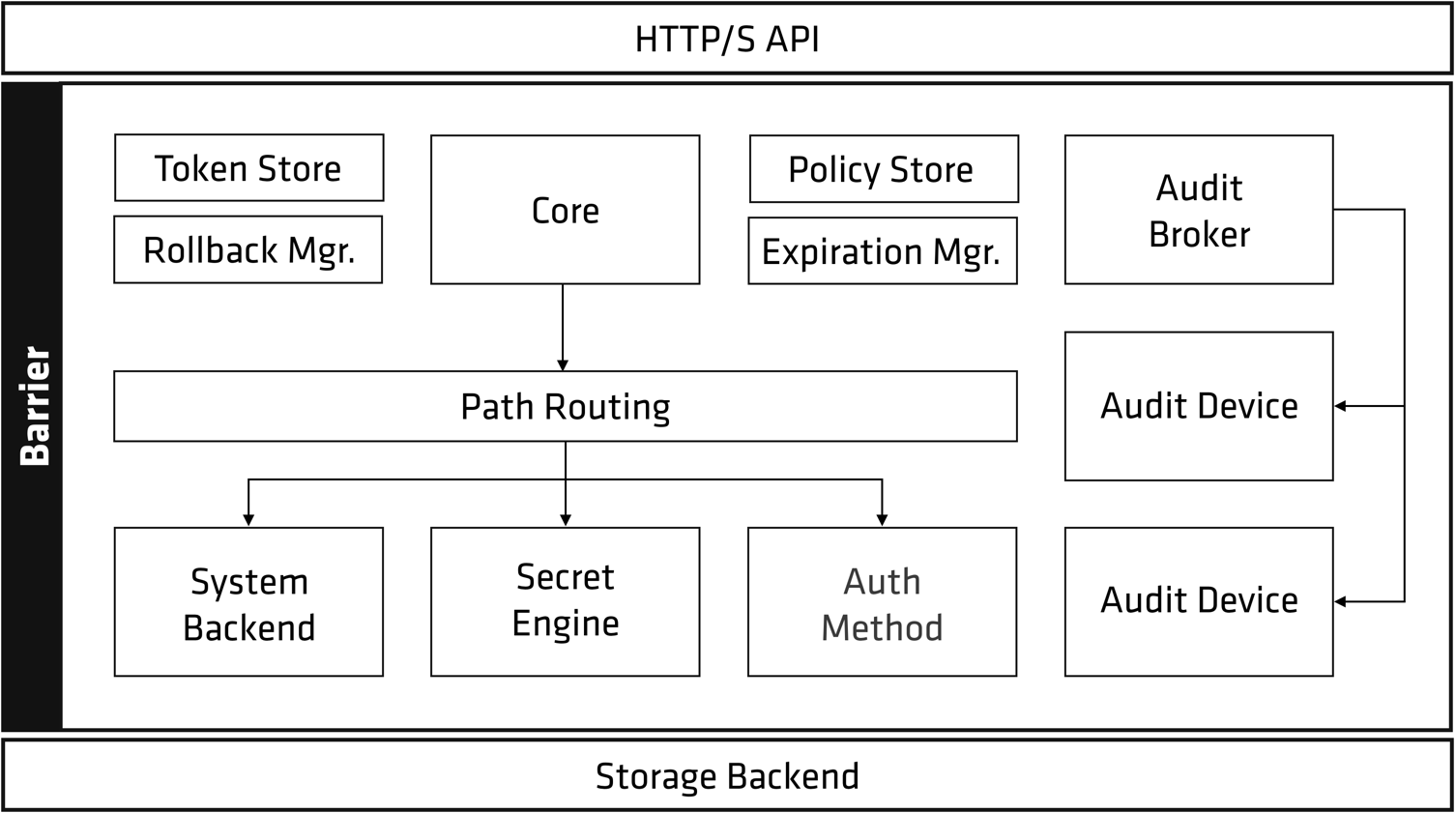
从以上架构图可以看到,几乎所有的 Vault 组件都被统称为 Barrier (屏障)
Vault 架构可以大体分为三个部分: [7]
Sotrage Backend - 存储后端Barrier - 屏障层HTTPS API - API 接口
常用概念
Storage Backend - Vault 自身不存储数据,因此需要一个存储后端(Storage Backend),存储后端对 Vault 来说是不受信任的,只用来存储加密数据。 [8]
Initialization - Vault 在首次启动时需要初始化(Initialization),这一步会生成一个 Master Key(加密密钥)用于加密数据,只有加密完成的数据才能保存到 Storage Backend
Unseal - Vault 启动后,因为不知道 Master Key (加密密钥)所以无法解密数据(可以访问 Storage Backend 上的数据),这种状态被称为 Sealed(已封印),在能解封(Unseal)数据之前,Vault 无法进行任何操作。Unseal 是获取 Master Key 明文的过程,通过 Master Key 可以解密 Encryption Key 从而可以解密存储的数据 [6]
Master Key - Encryption Key (用来加密存储的数据,加密密钥和加密数据被一同存储) 是被 Master Key(主密钥) 保护(加密),必须提供 Master Key,Vault 才能解密出 Encryption Key,从而完成数据解密操作。Master Key 与其他 Vault 数据被存放在一起,但使用另一种机制进行加密:解封密钥 ,解封密钥默认使用 沙米尔密钥分割算法 生成 Key Shares [9]
Key Shares - 默认情况下,Vault 使用 沙米尔密钥分割算法 将 Master Key 的解封密钥分割成五个 Key Shares(分割密钥),必须要提供其中任意的三个 Key Shares 才能重建 Master Key,以完成 Unseal(解封)操作
Key Shares(分割密钥)的总数,以及重建 Master Key(主密钥)最少需要的分割密钥数量,都是可以调整的。 沙米尔密钥分割算法 也可以关闭,这样主密钥将被直接提供给管理员,管理员可直接使用它进行解封操作。
认证系统及权限系统处理流程
在解密出 Encryption Key 后,Vault 就可以处理客户端请求了。 HTTPS API 请求进入后的整个流程都由 Vault Core 管理,Core 会强制进行 ACL 检查,并确保 Audit logging(审计日志)完成记录。
客户端首次连接 Vault 时,需要首先完成身份认证,Vault 的 Auth Method 模块有很多的身份认证方法可选
- 用户友好的认证方法,适合管理员使用,包括:
user/password、云服务商、ldap 等,在创建用户的时候,需要为用户绑定 Policy,给予适合的权限
- 应用友好的方法,适合应用程序使用,包括:
public/private keys、token、kubernetes、jwt 等
身份验证请求经 Core 转发给 Auth Method 进行认证,Auth Method 判定请求身份是否有效并返回关联的策略(ACL Policies)的列表。
ACL Policies 由 Policy Store 负责管理与存储,Core 负责进行 ACL 检查,ACl 的默认行为是 Deny,意味着除非明确配置 ACL Policy 允许某项操作,否则该操作将被拒绝。
在通过 Auth Method 进行认证,并返回了没有问题的 ACL Policies 后,Token Store 会生成并管理一个新的 Token,这个 凭证 会返回给客户端,用于客户端后续请求的身份信息。Token 都存在一个 lease(租期)。Token 关联了相关的 ACL Policies,这些策略将被用于验证请求的权限。
请求经过验证后,将被路由到 Secret Engine,如果 Secret Engine 返回了一个 secret,Core 将其注册到 Expiration Manager,并给它附件一个 Lease ID,Lease ID 被客户端用于更新(renew)或者吊销(revoke)它得到的 secret。如果客户端允许租约(lease) 到期,Expiration Manager 将自动吊销(revoke) 这个 secret
Secret Engine
Secret Engine 是保存、生成或者加密数据的组件,非常灵活。有的 Secret Engin 只是单纯的存储与读取数据,比如 kv(键值存储)就可以看作一个加密的 Redis。而其他的 Secret Engine 则可能连接到其他的服务并按需生成动态凭证等。