阴阳八卦
八卦总括
八卦 指 八个基础卦像,分别为 乾 坤 艮 兑 坎 离 震 巽 ,亦称为 经卦 、 单卦 、 三爻卦 ,是由 阳爻(—) 阴爻(--) 上下排列而成得一种 表述符号系统
八卦是易学体系的基础,先秦易学主要是 三易 ,即 夏代的连山(连山易) 、 商代的归藏 、 周代的周易 ,后世人们熟悉的是周易,它分为易经和易传。
| 八卦 | 卦象/类相 | (经典易学)阴阳属性 |
|---|---|---|
| 乾 ☰ | 天、父、马、头、寒、冰 | 纯阳 |
| 坤 ☷ | 地、母 、牛、腹 | 纯阴 |
| 震 ☳ | 雷、长男、龙 、足 | 少阳 |
| 巽 ☴ | 风 、长女、鸡 、股 | 少阴 |
| 坎 ☵ | 水、中男、豕 、耳 | 阳 |
| 离 ☲ | 火、中女、雉 、目 | 阴 |
| 艮 ☶ | 山、少男、狗 、手 | 阳 |
| 兑 ☱ | 泽 、少女、羊、口 | 阴 |
宋代朱熹的《周易本义》写了《八卦取象歌》帮人记卦形:
- ☰ 乾三连
- ☷ 坤六断
- ☳ 震仰盂
- ☶ 艮覆碗
- ☲ 离中虚
- ☵ 坎中满
- ☱ 兑上缺
- ☴ 巽下断
豕(shǐ) 指猪,特别是指古代所说的家猪。常见于古文、典籍和卦辞中,用于象征 贪婪、污秽或愚昧,有贬义。 。《易经》六十四卦中有一卦叫 豕负涂 ,《象传》:“豕负涂,畜不洁也。”
雉鸡 ,又称野鸡,是一种野生鸟类,雄鸟羽毛鲜艳,尾巴较长,叫声高亢。《诗经》《左传》等古文中多有“雉”出现,常用于比喻、美化或象征。
八卦中三爻结构的意义 :
- 下爻(初爻) :内在、初始,代表事物萌发,如震卦阳爻在下,象征春雷破土
- 中爻 :发展过程、核心和本质,如坎卦中爻为阳,表水之流动内核
- 上爻 :外在、结果或转化,如艮卦阳爻在上,象山之稳固终成
阴阳变化之理
八卦中的阴阳是处于动态变化中的,阳主动、阴主静,在数理上,阳为奇、阴为偶。在数字里面,奇数不均衡(不平衡),不平则会动,因此有动态性;偶数平衡,平衡则保持不动,因此有静态性。
我们知道现代数学中,数字奇偶特性中有这么一条: 奇数加上奇数会变为偶数,偶数加上奇数会变为奇数;奇数加上偶数依旧是奇数,偶数加上偶数依旧是偶数 , 遵循 奇变偶不变
阴阳变化于此相同: 阳动,加阳属性,状态会变;阴静,加阴属性,状态不变 。在阴阳状态中,阴变即为阳,阳变即为阴。
- 阳加阳变阴
- 阴加阳变阳
- 阳加阴为阳
- 阴加阴为阴
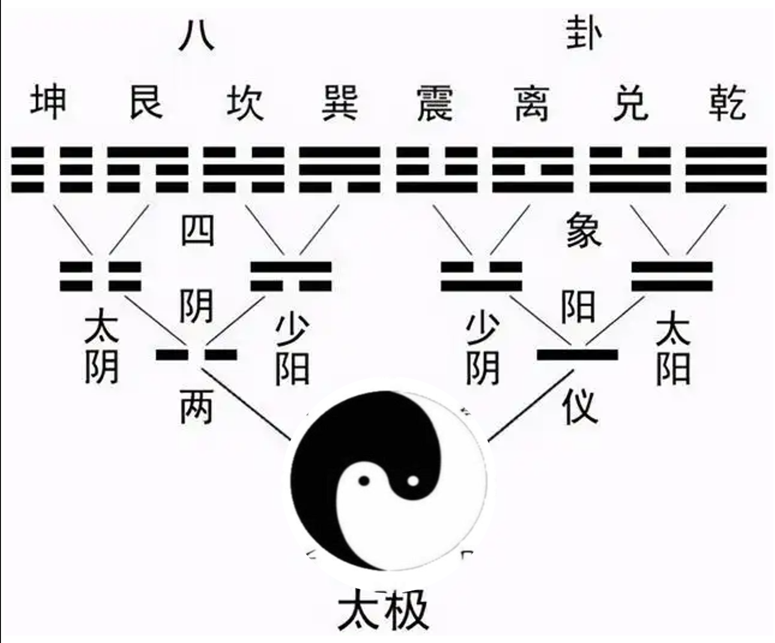
太极两仪四象八卦
太极就是一,是道 ,是天地未分时物质性的浑沌元气。
太极动而生阳 — ,静而生阴 -- , 是为 两仪,阴阳互为其根( 孤阳不生,独阴不长,一阴一阳之谓道 ),分别代表主动、刚健的阳性力量和被动、柔顺的阴性力量。这一过程既是符号的诞生,也是宇宙从 “无” 到 “有” 的第一次质变。
太极图 体现得是 太极 –> 两仪(阴 ⚋ 阳 ⚊ )–> 四象(太阳 ⚌ 、 少阴 ⚍ 、少阳 ⚎ 、太阴 ⚏ )的过程,这个体系中只看 (阴阳)气的多少 ,表示 阴阳的程度或 动态 变化
两仪的符号特性直接关联数理: 阳爻为奇数 1,阴爻为偶数 2 ,奠定了后续推演的数理基础。在哲学层面,两仪象征天地、昼夜、男女等二元对立,但其本质是 阴阳互根 —— 阳中含阴(如阳爻中间可视为虚), 阴中藏阳 (阴爻两端实而中虚),体现对立统一的辩证思维。
两仪通过 一分为二 的叠加,生成四种组合形态,即 四象
| 四象 | 季节 | 方位 | 五行 | 阴阳趋势 |
|---|---|---|---|---|
| 太阳 ⚌ | 夏 | 南 | 火 | 阳盛、阳极、阳最旺 |
| 少阴 ⚍ | 秋 | 西 | 金 | 阳中阴生(阴刚开始增强、阳退) |
| 少阳 ⚎ | 春 | 东 | 木 | 阴中阳生(阳刚开始增强) |
| 太阴 ⚏ | 冬 | 北 | 水 | 阴盛、阴极、阴最旺 |
四象的生成逻辑遵循 阴阳互含 原则:老阳(太阳)虽为纯阳,但其爻画叠加隐含 阳极生阴 的转化趋势;老阴(太阴)同理,阴极必返阳。这种动态消长关系,在太极图中表现为阴阳鱼的 “S” 形旋转,阳鱼头部含阴眼,阴鱼头部藏阳眼,直观呈现 “物极必反” 的规律。
在 四象 之上,叠加阴阳,形成 八卦
| 四象 | 上加一阳 | 上加一阴 | 所得两卦 | 家庭伦理 |
|---|---|---|---|---|
| 太阳 ⚌ | ☰ 乾 | ☱ 兑 | 父 / 少女 | |
| 少阴 ⚍ | ☲ 离 | ☳ 震 | 中女 / 长男 | |
| 少阳 ⚎ | ☴ 巽 | ☵ 坎 | 长女 / 中男 | |
| 太阴 ⚏ | ☶ 艮 | ☷ 坤 | 少男 / 母 |
将两个 八卦(单卦) 上下组合,即可形成 六十四卦,称为 重卦
经典易学(《说卦传》通行) 中八卦得阴阳属性判断(“卦之阴阳”, 不分先天八卦和后天八卦)用的是 单卦中阳爻(阳为 1,阴为 2 计数,三卦符画总数为奇数为阳)的奇偶 这一标准。可以用以下方法快速确认卦之阴阳:
看 主爻(最少得阴爻或者阳爻) 得阴阳,阳爻为主即阳卦,阴爻为主即阴卦
阳卦 : 卦中仅有一阳爻(奇数)—— 震 ☳、坎 ☵、艮 ☶
阴卦 : 卦中仅有一阴爻(阳爻为偶数二)—— 巽 ☴ 、离 ☲、兑 ☱
乾坤为纯阳、纯阴,自为阳、阴之宗
现在的八卦 分为 先天八卦、后天八卦、中天八卦 。邵雍之前,没有区分不同八卦体系。继承陈抟道家易学的他,在《皇极经世》、《梅花易》等公开了很多易学的较高级知识,包括二种八卦的区分。他把由一分为二而来的 天地定位 的八卦位图称为 先天八卦 ,又名 伏羲八卦 ,把《说卦传》 帝出乎震 一段谈的八卦称为 后天八卦 ,也名 文王八卦 。朱熹《周易本义》采用邵子说法和图子,使得其说流行。
乾坤生六子
原文出自《易传·说卦传》:
乾知大始,坤作成物。乾坤有变,辟天地,成列卦,而播其气。乾坤生六子,六子发展而为八卦。八卦定吉凶,吉凶生大业。
乾,天也,故称乎父;坤,地也,故称乎母。震一索而得男,故谓之长男;巽一索而得女,故谓之长女;坎再索而得男,故谓之中男;离再索而得女,故谓之中女;艮三索而得男,故谓之少男;兑三索而得女,故谓之少女。
这一理论以 父母生子女 的家庭伦理为隐喻,阐释了八卦 中乾(父)、坤(母) 与其余六卦(六子)的生成关系,体现了阴阳交感、万物化生的哲学思想。
乾坤生六子 的核心是通过 乾卦 ☰(纯阳)与坤卦 ☷(纯阴) 的爻位交感,模拟父母生育子女的过程,其中 索 意为 求索、交感、交换,即 乾卦向坤卦索取阴爻,或坤卦向乾卦索取阳爻 ,根据 “索求” 的爻位(初爻、中爻、上爻)和性别( 阴生阳、阳生阴 )生成六子卦:
- 乾 ☰ 坤 ☷ 索初爻而得 震 ☳ 巽 ☴,为长男长女
- 乾 ☰ 坤 ☷ 索中爻而得 坎 ☵ 离 ☲,为中男中女
- 乾 ☰ 坤 ☷ 索上爻而得 艮 ☶ 兑 ☱,为少男少女
乾(阳)与坤(阴)交 感是六子卦生成的前提,体现 一阴一阳之谓道 的核心思想 —— 孤阳不生,独阴不长,只有阴阳相互作用,才能化生万物 。如震卦(阳爻在下)象征 “阳动于内”,巽卦(阴爻在下)象征 “阴生于下”,二者对应阴阳初动的状态。
先天八卦
邵雍称 先天八卦 为 伏羲八卦 ,先天八卦图 通常与 太极图 搭配出现, 太极就是阴阳合一的混元、混沌 ,因此一些人把 太极式先天八卦称为混元八卦 。

先天八卦图(伏羲):按生成次序排成圆,天南地北,离东坎西,体也。 方位为: 乾南、坤北、离东、坎西、兑在东南、艮在西北、巽在西南、震在东北。
先天八卦的主要依据在《周易·说卦传》:“ 天地定位,山泽通气,雷风相薄,水火不相射。八卦相错,数往者顺,知来者逆,是故易逆数也 ”。
天地定位 乾为天,纯阳,在上;坤为地,纯阴,在下,天地之位已定,阴阳得其所。确定了宇宙空间得基本秩序于方位(上下),象征着宇宙万物初始得定位。
山泽通气 艮为山,山属静,主止;兑为泽,泽属润(动,悦),一静一动,一高一低,气脉相通,互相作用,山中有水可成泽,泽水渗透滋润山体,两者气息相通,反映事物间相互交融、相互影响,这是 通变 的思想,动静互根、高低互补。
雷风相簿 震为雷,为动;巽为风,为入。 相薄即互相逼近、交互、逼迫、摩擦、激荡 。雷动风发,二者相互搏击,体现了事物间相互作用、相互激荡的动态过程。春雷惊蛰时,雷声震动大地,东风(巽)随之吹拂,雷动则风从,风助则雷威,二者协同唤醒万物生机(如 “雷以动之,风以散之”)。震为 “长男”(阳刚主动),巽为 “长女”(阴柔顺势),象征自然中 “动力与传导” 的联动 —— 雷是能量爆发的起点,风是能量扩散的载体,二者共同推动事物的生长变化。
水火不相射 坎为水;离为火。水属阴,火属阳,属性相反。“射”表示相对、互对。水火虽属性相反,但不相互排斥、各安其位又相互依存。坎为 “中男”(阳藏于阴),离为 “中女”(阴含于阳),体现 “阴中有阳、阳中有阴” 的辩证关系
先天八卦图经常和太极图一起,他们的对应关系体现了,阴阳(两仪)得变化,太极图中白色象征阳,黑色象征阴。从太极图来看,阳气在北方最盛时,阴气开始回返,从巽卦到坎卦、艮卦,再到坤卦(正北方),阴气逐渐强盛,坎卦取自东方(离位)的黑中白点,象征二阴爻含一阳爻,为阳卦;阴气在北方最盛,阳气由此开始渗透,从震卦到离卦、兑卦,再到乾卦(正南方),阳气逐渐强盛,离卦取自西方(兑位)的白中黑点,象征二阳爻含一阴爻,为阴卦。
先天八卦数
先天八卦数 也称为 先天八卦生成数,是根据 阴阳二分法 生成的八卦顺序,是天地自然之数,体现阴阳相生之序 。 其为八卦所生的序数:
- ☰ 乾 1
- ☱ 兑 2
- ☲ 离 3
- ☳ 震 4
- ☴ 巽 5
- ☵ 坎 6
- ☶ 艮 7
- ☷ 坤 8
数字 1-8 对应八卦从 纯阳 到 纯阴 的完整分化过程,如 乾 1 为 天之初,坤 8 为 地之成,中间六卦为天地交感的中间状态。
先天八卦数于节气结合看,对应四季的阴阳消长: ☲ 离 3 对应 春风 之时,☵ 坎 6 为 秋分 之时; ☰ 乾 1 和 ☷ 坤 8 分别代表 夏至纯阳 和 冬至纯阴
实际应用中, 先天八卦取数,后天八卦取向 。先天八卦数:乾一、兑二、离三、震四、巽五、坎六、艮七、坤八。 后天八卦方向 :震卦,正东;巽卦,东南;离卦,正南;坤卦,西南;兑卦,正西;乾卦,西北;坎卦,正北;艮卦,东北。实际应用时最多就是后天八卦,先天卦用得很少。
先天八卦方位 与 先天卦数 的排列形式,由 乾一 至 震四,系 由上而下 , 再由下而上旋至巽五,由巽五至坤八又由上而下 ,其路线形成 S 形的曲线,这种运动方式称为 逆行 ,从 S 的迹形运动中,由乾至坤是按先天卦数 乾一、兑二、离三、震四、巽五、坎六、艮七、坤八 排列的,这种从上而下,先左后右,由少至多的数字排列方式,称作 逆数
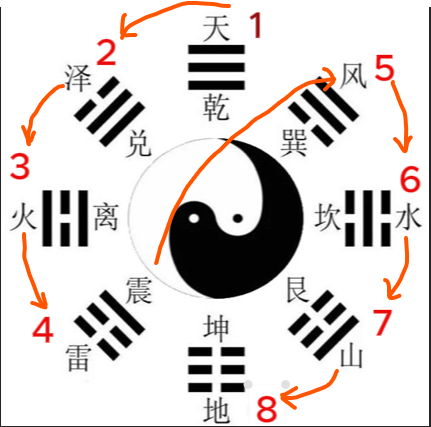
反之,由 坤至乾,从下面的开始,由下而上,先右后左,由多至少 的数字形成倒行的方式,称作 顺数 。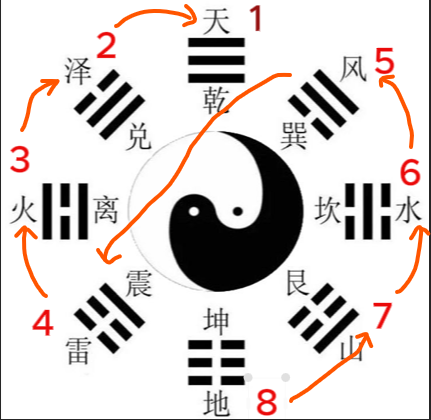
按先天八卦 乾坤、艮兑、震巽、坎离 两两对待之本,每一对中都含有 顺逆、奇偶、阴阳 ,即 阴中含阳,阳中含阴,阴阳错综交变 ,这就是先天八卦方位图中的矛盾对立统一的辩证思想,是八卦本着阴阳消长,顺逆交错,相反相成的宇宙生成自然之理,来预测推断世间一切事物,数不离理,理不离数。
先天八卦中,相对位置的卦数相加和都为 九,如 乾 1 加 坤 8、兑 2 加 艮 7。 九为阳数
先天八卦时间表
先天八卦,在时间上,从坤始,到艮止,顺时针排一圈就是一个循环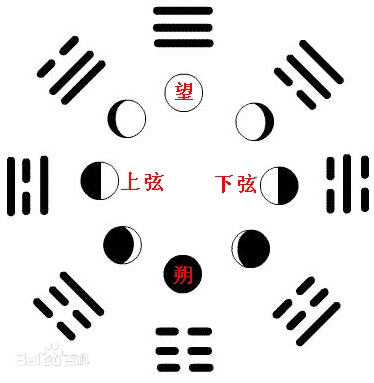
| 坤☷ | 震☳ | 离☲ | 兑☱ | 乾☰ | 巽☴ | 坎☵ | 艮☶ | |
|---|---|---|---|---|---|---|---|---|
| 先天数 | 8 | 4 | 3 | 2 | 1 | 5 | 6 | 7 |
| 节气 | 冬至(纯阴) | 立春(阳始生) | 春分 | 立夏 | 夏至(纯阳) | 立秋(阴始生) | 秋风 | 立冬 |
| 月份 | 子(十一)月 | 寅(一月) | 卯(二月) | 巳(四月) | 午(五月) | 申(七月) | 酉(八月) | 亥(十月) |
| 月相 | 朔(新月) | 残月 | 上弦月 | 盈凸月(月亏、满月前) | 望(满月) | 残月(月盈、满月后) | 下弦月 | 峨眉月(新月前) |
| 日期 | 初一、二(无月) | 初四、五 | 初七、八 | 十二、十三 | 十五、十六 | 二十前后 | 廿三、廿四 | 廿七、廿八 |
| 时间区间 | 23-2 点 | 2-5 点 | 5-8 点 | 8-11 点 | 11-14 点 | 14-17 点 | 17-20 点 | 20-23 点 |
| 核心象征 | 地 母 纯阴、阴盛 |
雷 长男 震动、阳气初发 |
火 中女 光明、外阳内阴 |
泽 少女 喜悦、阳中藏阴 |
天 父 纯阳、极致光明 |
风 长女 入藏、阴气初萌 |
水 中男 险陷、外阴内阳 |
山 少男 、止息、阴气收敛 |
后天八卦
后天八卦 相传为 周文王 所创,又叫 文王八卦 。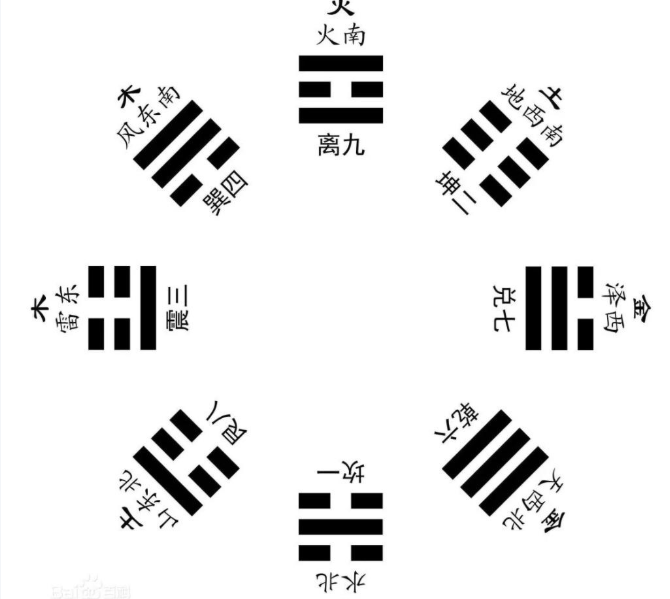
《周易・说卦传》: 帝出乎震,齐乎巽,相见乎离,致役乎坤,说言乎兑,战乎乾,劳乎坎,成言乎艮
帝出乎震 - 帝,指主宰四时万物运行的 阳气、天心、生机。 震 为 雷 ,冻土解冻,万物开始萌发,阳气始盛,是万物萌发的起始 。震居东方卯位,春分时节,太阳直射赤道,昼夜平分,万物萌动,故曰 出 。
齐乎巽 - 齐,为 整齐、一致、调顺。巽为风,阳气继续生发,阴气渐消, 立夏前后 ,雷以动之,风以散之,万物整齐生长,摆脱萌发期的稚嫩,进入稳定生长(发展)阶段。 巽为 长女,象征柔顺中的渗透力 —— 风虽柔,却能推动万物同步生长,如政令风行则秩序齐整,对应人事中 “协调、疏导” 的阶段。
相见乎离 - 夏至阳极,光照最盛,万物繁茂而 相见 于人世。万物在离卦阶段繁茂彰显,彼此相见、光明普照,万物的形态、特性完全展露。 离为 中女,象征外显的美丽与附着(“离,丽也”) ,如人事中事业鼎盛、才华显露,或人际关系明朗公开。
致役乎坤 - 坤,为地为母,性顺承、载育、厚重。立秋前后,万物赖地力以养,故称 致役(服役于地,使众效力)。万物在坤卦阶段依赖大地承载滋养,完成孕育成熟的使命。
说言乎兑 - 兑,为泽、悦(说 通 悦、喜悦)、口舌,对应秋风之时,万物在兑卦阶段收获成熟(谷物成熟、果实饱满),呈现喜悦之态。泽能滋润万物,也象征收获后的甘甜与满足。此时阳气继续收敛,阴气上升,自然节律从 “生长” 转向 “收藏”。兑为 “少女”,象征愉悦与沟通,对应人事中 “收获、分享” 的阶段,如成果落地、人际和谐。
战乎乾 - 乾,为天为父、刚健。节气对应 立冬 前后,万物在乾卦阶段面临阴阳相争,阴气欲进,阳气潜藏,准备蛰伏。乾的 刚健 在此体现为阳气虽退,却暗藏不屈之力(“潜龙勿用” 之象)。 乾为 父,象征权威与收敛 ,对应人事中 “竞争、蛰伏” 的阶段,如事业需收敛锋芒,应对挑战。
劳乎坎 - 坎,为水,冬至阴极,万物闭藏,阳气潜回地下,若劳而后息。万物经过一年的生长、收获,能量耗尽,需进入潜藏状态休养(“劳” 即 “劳累后需休息”)。水善藏于地下,象征阳气在地下蛰伏,等待来春复苏。此时天地冰封,万物静默,为 “劳而藏” 的阶段。 坎为 中男,象征内敛与潜藏 ,对应人事中 “沉淀、蓄能” 的阶段,如蛰伏待机、厚积薄发。
成言乎艮 - 艮,为山为止,为成为定,节气对应 立春 前后,万物在艮卦阶段完成一年循环,终结旧周期,开启新生机。 成 即 完成、终结 ,阳气在潜藏后开始回升,但尚未完全发动,处于 “止而待发” 的状态。 山象征稳固与界限,标志着 “收藏” 的终结,也预示 “生长” 的开端(“止者,事之终也;止而不止,事之始也”) 。艮为 “少男”,象征终止与新生,对应人事中 “总结、蓄力” 的阶段,如旧业终结,新计划酝酿。
后天八卦以方位为空间框架(东→东南→南→西南→西→西北→北→东北),以四季流转为时间线索(春→夏→秋→冬→春),构建了万物从 “生”(震)、“长”(巽、离)、“收”(坤、兑)、“藏”(乾、坎)到 “成”(艮)的闭环,周而复始,永无停息:
- 生 : 震(春生) —— 阳气启动,万物萌发;
- 长 : 巽(整齐生长)、离(繁茂彰显) —— 阳气鼎盛,万物舒展;
- 收 : 坤(承载养育)、兑(收获喜悦) —— 阳气渐收,万物成熟;
- 藏 : 乾(阴阳相争)、坎(潜藏休养) —— 阴气主导,万物蛰伏;
- 成 : 艮(终结新生) —— 旧周期结束,新循环待启。
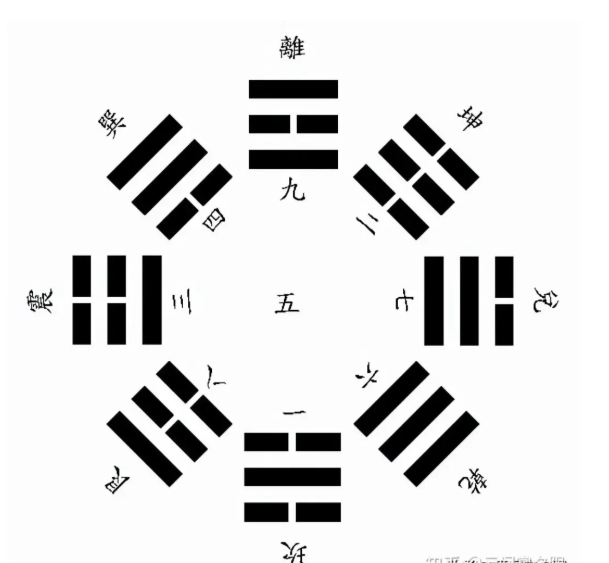
后天八卦 得方位为: 震东、兑西、离南、坎北、巽东南、坤西南、乾西北、艮东北
后天八卦中,四个阳卦( 乾 ☰、坎 ☵、艮 ☶、震 ☳ )位于 左下侧 ,四个阴卦( 坤 ☷、离 ☲、巽 ☴、兑 ☱ )位于 右上侧 ,如下图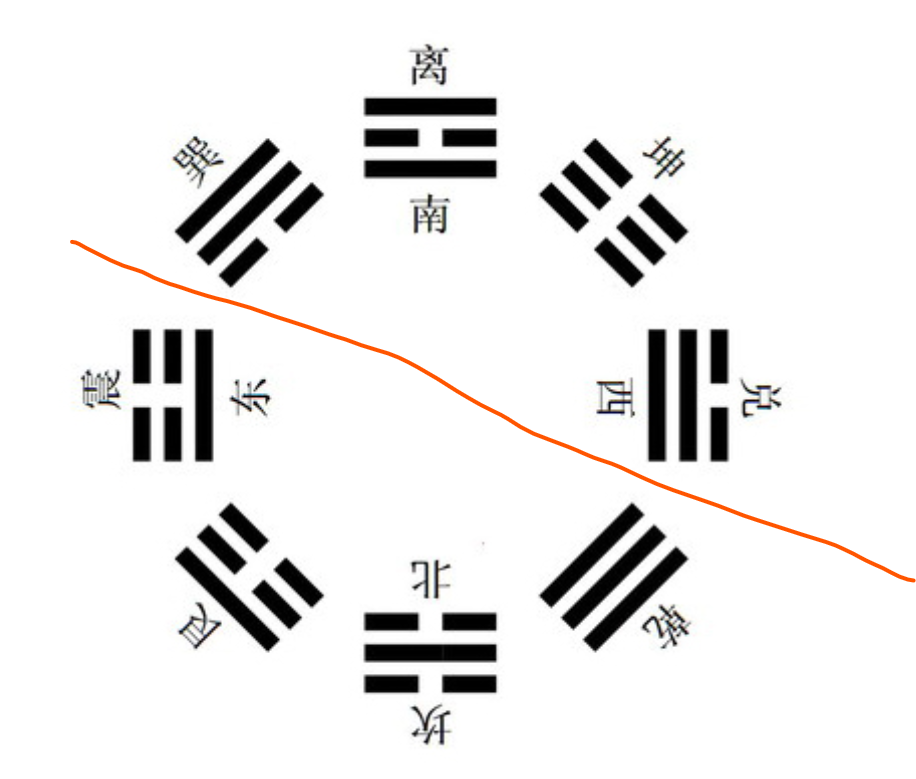
邵子曰:“乾统三男于东北,坤统三女于西南,乾、坎、艮、震为阳,巽、离、坤、兑为阴”。
后天八卦 以 震卦 ☳ 为始, 位列正东 ,按顺时针方向,依次为 巽卦,东南;离卦,正南;坤卦,西南;兑卦,正西;乾卦,西北;坎卦,正北;艮卦,东北;震卦,正东 。
后天八卦与时间
| 震☳ | 巽☴ | 离☲ | 坤☷ | 兑☱ | 乾☰ | 坎☵ | 艮☶ | |
|---|---|---|---|---|---|---|---|---|
| 后天数 | 3 | 4 | 9 | 2 | 7 | 6 | 1 | 8 |
| 节气 | 春分 | 立夏 | 夏至 | 立秋 | 秋风 | 立冬 | 冬至 | 立春 |
| 月份 | 卯 | 巳 | 午 | 申 | 酉 | 亥 | 子 | 寅 |
| 核心象征 | 地 母 纯阴、阴盛 |
雷 长男 震动、阳气初发 |
火 中女 光明、外阳内阴 |
泽 少女 喜悦、阳中藏阴 |
天 父 纯阳、极致光明 |
风 长女 入藏、阴气初萌 |
水 中男 险陷、外阴内阳 |
山 少男 、止息、阴气收敛 |
后天八卦数
后天八卦数出自 《洛书》,其中 五 为 中宫 :
- 坎☵ 一
- 坤☷ 二
- 震☳ 三
- 巽☴ 四
- 乾☰ 六
- 兑☱ 七
- 艮☶ 八
- 离☲ 九